Learning Chinese Characters the Smart, Fast and Efficient Way
With China growing in importance in the world’s economy, more and more people want to learn the Chinese languages, both written and spoken.
However, the written Chinese characters are not based on an alphabet. There literally hundreds of thousands of characters that have been used throughout history.
While the most common 3,500 modern characters account for 99% of those seen in written Chinese, that is still a huge task even for the most dedicated student.
There seems no alternative, but to rote learn all these characters. This is hard even for native Chinese speakers, and there’s been growing concern that there is no smart of more efficient way of learning these characters.
However a new study by Jinshan Wu, a physicist at Beijing Normal University, and colleagues has found a more efficient method based on network theory to examine the structural relationships between Chinese characters and their components.
This offers a smarter, simpler and more economic strategy for learning Chinese characters that is outlined and reviewed in this article.


Despite their appearance, the structure of Chinese characters isn’t as arbitrary and diverse as they appear.
There is no alphabet as such, but most charcters are made up of a limited number of sub-characters or radicals, which themselves consist of a standard set of marks, or strokes.
The radicals themselves often contain hints about pronunciation or meaning because of their derivation.
This gives rise to a’family’ of characters containing the same radicals, with related meanings.
The classic example is ‘three’s a crowd – three trees is a forest.
Once you learn that tree is 木 (mu), it’s not so hard to remember word and forest that are derived by repeating the character.



Using the liu shu rules, Wu and colleagues used network software to develop a network map of the structure or ‘taxonomy’ for all 3,500 of the common characters.
Their research showed that there were about 224 radicals, a type of alphabet, that were combined to from about 1,000 character elements that were in turn combined to form the 3,500 common characters.
The network ‘tree’ they produced is shown below. When expanded to full size you can see it contains all of the characters. The full size tree is available from their website.
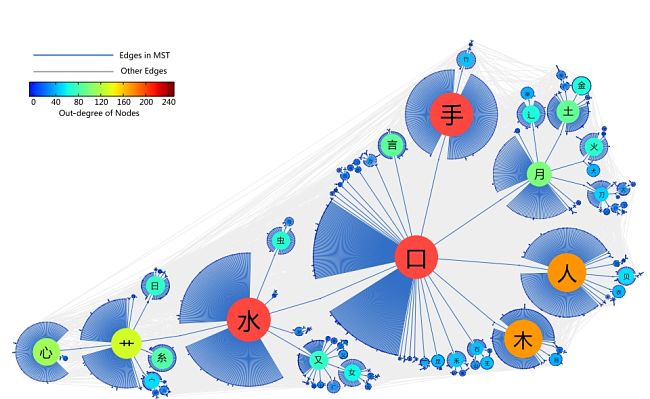
The structure is hierarchical tree with several central nodes (trunks) consisting of the more commonly used radicals. More details are available from the researsher's website. The nodes then branch out by combining with other radicals, through the network to the branch tips. The example below shows how the network works at a fine scale
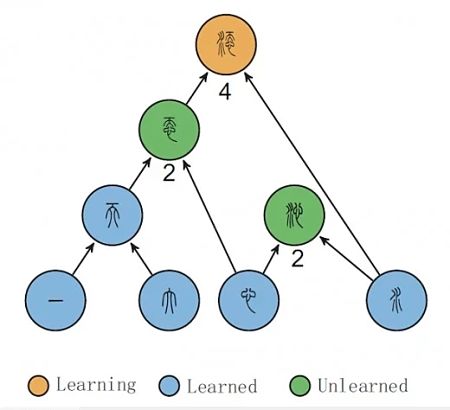
How is this Network Useful?
The researchers argued that it provides a pathway of directed learning focused on the more commonly occurring radicals and character elements first. Starting at the trunks means reapplying the elements learnt, and progressing to the lower levels of the hierarchy – the branch tips.
Combine this with learning the most commonly occurring characters and radicals first, this provides an efficient way of learning the characters. The top 200 characters, used by themselves, or in combination are shown below (derived from their website).
Top 100 Characters

Is the Network Method More Efficient and Moe Cost-Effective for Learning Chinese Characters?
The researchers argued that that it is more efficient to learn a multi-part character by first learning the components from which it is derived. The alternative is rote learning. Knowing the derivation of the characters may also improve the ability to memorise the characters.

Essentially the researchers showed that the “cheapest” way to learn all 3500 characters is to start with the “trunk” characters. These central characters have the highest number of branches linked to them. This means that you can reuse what you have already learned to go on and learn other characters containing the same elements.
The strategy developed also uses the usage frequency as part of the priority weighing. This means that the learning pathway moves gradually through the network focusing on the most commonly used characters first.
The researchers developed a new learning method, which they called the distributed node weight (DNW) strategy. Weighted importance and priority values are assigned to elements based on the weight of the nodes, and the hierarchical structure of the network.
The researcher’s analysis showed that DNW method significantly outperformed existing teaching methods.
Of course, the ultimate test of the benefits of this approach is to test whether students do actually learn Chinese characters faster. These tests have not been done so far.